Stop Paying People to Read Documents and Type Numbers Into Spreadsheets
We build custom AI pipelines that pull the data you need from any document, fast, cheap, and ready for decisions. 99%+ accuracy. No more manual entry. No more waiting.
How Extraction Works
Every pipeline is built around your documents
We configure each pipeline to extract the exact fields you need, with source citations so every value is verifiable. Data flows straight into your existing systems.
Your pipeline extracts different fields, matches your schema, and connects to your own systems.
Proven Results
See What We Built for Teams Like Yours
Furniture: Automating Tender Bids
A major furniture manufacturer bidding on government contracts was leaving money on the table. Their team couldn't review tender documents fast enough to respond before deadlines closed.
- Tender review from 4 hours to 20 minutes.
- Catalogue matched to requirements automatically.
- Saving £100s in staff costs per tender.
- More bids submitted per week.
- Fewer costly errors.
Triathlon: Replacing Manual Data Entry
A triathlon results network was paying outsourced workers by the hour to manually type up race results from PDF documents. The process was slow, expensive, and full of human error.
- 20 seconds vs. days of waiting.
- Better than human accuracy.
- ~1p per document vs. £10+ in contractor costs.
- Staff time reclaimed for growth, not managing contractors.

Automotive: Processing Messy Invoices
A parts distributor managing thousands of monthly invoices from a fragmented supplier network.
- Fewer data entry errors across the board.
- Faster PO-to-invoice reconciliation.
- Accounts payable staff freed up to handle exceptions, not data entry.
Legal: Tracking Global Regulations
A compliance platform needed to track regulatory changes across 50+ nations for their enterprise clients.
- Enabled a 'Real-Time Monitoring' product tier.
- Scalable architecture processing 10,000+ pages/day without additional headcount.
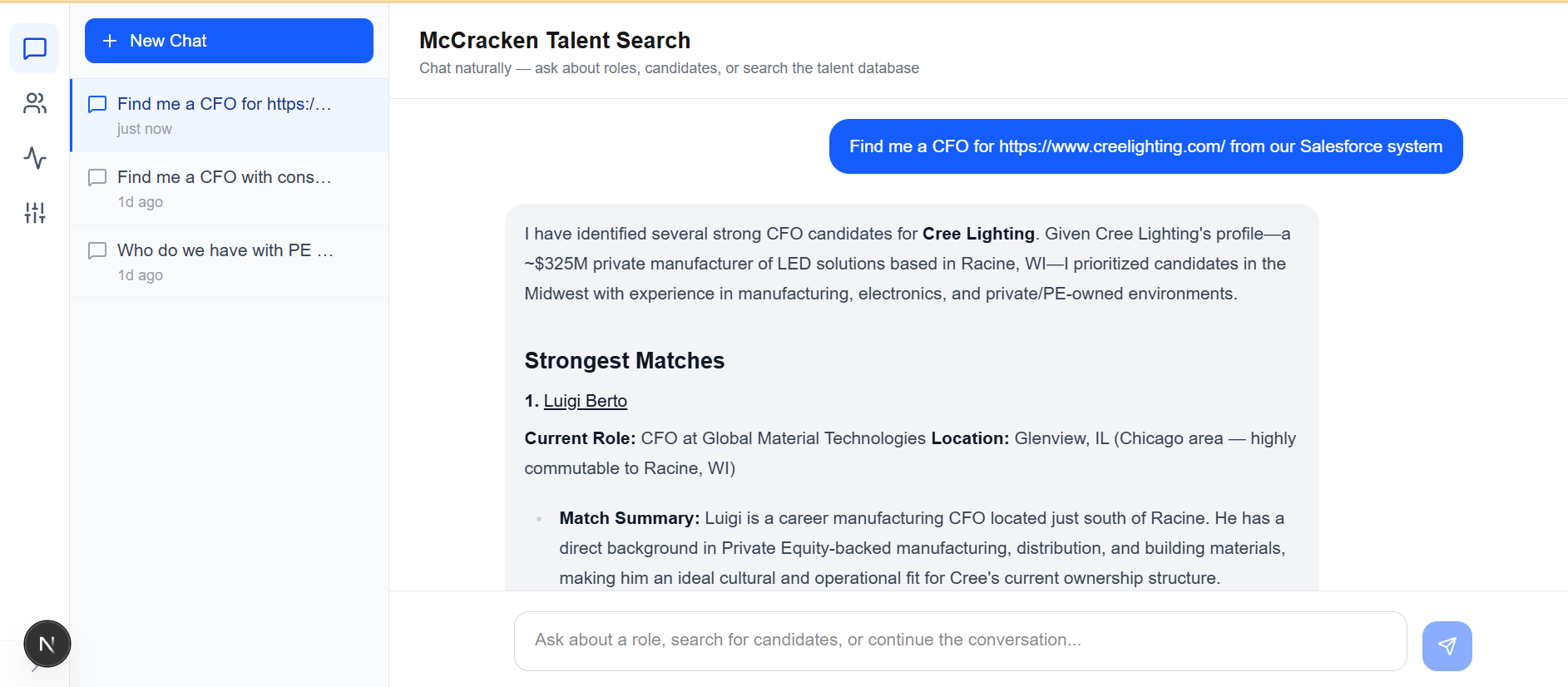
Talent Intelligence Platform
An executive search firm needed to replace a fragmented manual workflow (exporting data, running enrichment tools, uploading JSON to ChatGPT) with a single system connected to Salesforce.
- Zero manual data exports or file management.
- Automated LinkedIn enrichment with rolling 90-day refresh.
- AI chatbot with configurable matching outperforming generic ChatGPT.
What Clients Say
Teams that stopped re-keying data and never looked back
We used to outsource data entry for our race results, paying by the hour and waiting days to get files back. Half the time there were errors we had to fix ourselves. Spectract built a pipeline that does the whole job in seconds with near-perfect accuracy. No more chasing contractors, no more bad labels, and it costs a fraction of what we were paying.
How We Work
We prove it works on your documents before you commit to a full build.
Every engagement starts with a one-week proof of concept on your actual files. We build a working extraction pipeline, score it for accuracy, and map out what the full solution looks like. No guesswork, no vague promises. You see real results on real data before making any decisions.
Book a call
Tell us what your team processes manually. We figure out if it fits and scope the proof of concept.
One-week proof of concept
We build a pipeline on your documents and test it against your real data.
Review the results
Accuracy report, working demo, and a clear roadmap to full deployment.
Tell Us What You're Processing
Describe the documents your team handles manually. We'll tell you if a pilot makes sense and what accuracy to expect.